想进Kimi创作空间,挺简单。
这个功能在哪儿呢?就在聊天界面下面,有个不太显眼的按钮,上面写着:Kimi创作空间。
点进去后,会看到一个全新的创作界面,上面写着:你喜欢的歌都有它的视频。我们可以简称这个功能为:文生视频。
有没有拿到内测名额呢?快去看看。这个功能怎么用?进了创作空间,它有13个模板,比如:末日风格、赛博朋克、情书风格、哈利波特黑谷风格、摇滚风格等等。
操作步骤就两步:一,输入提示词;二,选择风格。然后等着生成就可以了。
如果你是新手,可能会问:怎么写音视频的提示词?别担心。在内容描述后面,有一个选项叫做“帮我写XX风格的提示词”。
点击这个选项,它会自动生成一两句描述相关内容风格的内容;整个过程不需要太多理解成本,只要会用AI,基本都会操作。
我试了三种风格:情书、末日和黑白复古。生成速度挺快的,随机点开一个生成的作品,是个14秒的音视频。
从视频人物来看,一眼就能看出是AI生成的,和真实人物修图后的质感不一样,模拟感比较重,这也是现在大多数模型的共同问题,不用太惊讶。
不过,好在它没有出现「恐怖谷脸」的情况。动作、表情和皮肤纹理都挺流畅,眼睛大小、牙齿排列和耳朵形状都没有问题,在人物呈现上整体很协调,这绝对是模型的一个进步。
再来说说场景。
我对近景、远景、特写和空镜都做了测试。我觉得远景效果最好,因为视角大,给人的整体感觉不一样。
我给远景设定的是音乐会现场,就像我们平时想的那样,能看到所有人举着手,还有灯光营造出的氛围,这方面它做得确实不错。
中景上,我给Kimi的提示词是这样:我告诉它,“秋天的公园,一对情侣在落叶中散步,女孩轻轻踢着地上的落叶,男孩伸手接住一片,然后笑着递给她”。
它生成的结果画面整体感觉挺秋天的,情侣之间的互动也表现出来了,但是,落叶的形状,情侣的表情动作这些细节没那么完美,还得再改进。
近景的效果一般,特写就不一样了,感觉挺真实的,甚至还有让人眼前一亮的地方。
我给近景的提示词是:
一张泛黄的情书静静地摊在古老书桌上,周围都是旧书和一支钢笔,自然光洒进来,情书纸页微微颤动,像是在讲过去的事。
它生成的画面挺清晰,把描述的场景呈现得不错,虽然和真实场景比起来还有点差距,但在特写上的表现已经超出了预期,让我看到了它在特定镜头上的潜力。
所以,在没有人物的特写场景上,Kimi还不错。

看到这,你也许会有疑问:为什么每个页面还能编辑呢?没错,在Kimi 创作空间里,音视频生成好了之后,有不满意的地方,可以针对每一帧进行单独创作。
比如:
你做了个14秒的视频,系统大概会分成12帧或13帧,每帧旁边都能单独写提示词,写完后,就能用新的提示词重新生成这一帧。这是个功能亮点。
如果你觉得模板里的音乐不好听,或者系统自带的音乐不合心意,可以输入链接,系统能提取音乐,还能上传自己的音乐,我看它现在能处理抖音的链接,挺方便。
对了,上传完音乐,选好模板,如果不知道怎么写提示词,也不用担心,只要输入几个关键词就行。
我选了“开始懂了”这首歌,在内容描述里写了恋人、公园、牵手、失落这些词,接着点“帮我写”的按钮,它就能生成一段话,省了不少事。
还有个好处,如果觉得生成慢,可以回到聊天界面,过一两分钟再回来,你的内容还在,不会影响生成。Kimi生成完内容后,会发短信通知你,这点挺方便的。
有优势总有劣势,我的感受有五点:
一,每次生成的视频时长有限,只能生成十几秒的视频;二,在个性化方面比较欠缺,如果想调整声音的语调之类的,系统不支持。
不过,也有个解决办法,是可以自己先录一段音频,把语调都调整好,然后再上传上去,这样就能弥补一些不足,但总归还是没有系统直接支持方便。
三,生成的视频质量有时不稳定。就像我之前说的,人物看起来和场景细节有时不够完美,不是每次都能达到最好的效果,而且风格模板虽然多,但有些风格比较笼统,不够细致。
比如:我想要特定年代或者情感的氛围,就很难精确做到。这对于对于细分场景下想用音视频的人来说,反而非常重要。
四,对于新手来说,即使有帮忙生成提示词的功能,有时生成的提示词还是挺模糊的,让人搞不清楚到底能做出什么样的视频,如果是专业视频制作人,他们可能也会有同样的烦恼。
还有一点,现在还不能分享作品,只能下载。我不知道这算不算一个很重要的功能。不过,根据使用其他平台的经验,好像这个功能也不是那么关键。
你也可以亲自体验下,看看感受如何?
不得不说,文生视频发展挺快,GIR报告说,2023年全球文生视频的市场收入大概有720万美元,预计到2030年能涨到22.19亿美元。这表示从2024年到2030年,每年的增长率可能会有56.6%。
感受不到数字带来的冲击也没关系,我们换个角度想。
现在广告、影视、教育领域对短视频的内容需求蛮大,大家都说行业不好做,裁员也多,其实公司大部分可重复、不用人力的工种的确在进一步被AI、或者会用AI的人替代。
2023年麦当劳就发布了一个全AI制作的广告。
这个广告把麦当劳的品牌元素巧妙地融入到生活场景里,比如动作细节、情绪状态等等,这种制作方式不仅让内容制作更快,还显示了AI在大量生产商业内容上的潜力。
还有伊利的《千年江南》和《伊笑过龙年》,这些视频用AI技术快速变换场景和面部表情,给广告增加了特别的情绪和视觉效果。
案例还有很多,不逐一列举。所以,这种尝试大大降低了广告制作成本,也说明了,AI生成视频已经成为广告创意的一个有效工具;它可能还不能直接做出一个完整的广告视频,但至少成了一个有用的辅助工具。
一说生成、我也很好奇,到底哪些人会用文生音视频?
AI技术发展先有技术,再逐步找到应用场景。但是推广的时候,就得反过来,得先有人愿意用,用的人多了,大家才会开始关注。
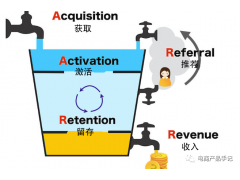
这个过程就像是PMF(Product Market Fit),就是产品和市场要匹配,需要不断调整。
我觉得,最开始用文生音视频的可能是自己做视频的人。比如:拍短视频的博主、做内容的创作者,或者是给客户服务的团队,这些人用了之后,提高了工作效率,慢慢就会吸引更多的服务公司来用。
而且,这项技术也可能会用在游戏、电影、电商这些地方。比如网易的《逆水寒》,里面很多角色是AI做的。还有像天猫、京东这样的电商平台,也开始用AI来做创意内容了。
从公司的角度来看,他们要功能很强的AI模型,能和他们的业务很好地结合,个人用户呢?希望模型操作简单,用起来方便,能快速帮他们解决问题。
这两者并不冲突,反而是相辅相成的。因为只有更多个人用户使用并反馈,模型才能不断优化,经过多次迭代,最终为企业客户提供更强大的服务。
可以说,个人用户的广泛使用为模型的成长打下基础,模型越成熟,就越能满足企业的需求,推动整个行业向前发展。
我看到Kimi最近在不断发力,比如:推出了数学版k0-math,悄悄测试文生音视频。这些动作其实展现了Kimi在向多模态技术发展的过程中,迈出的一些关键步骤。
为什么说这是关键一步呢?
先了解一下什么是多模态(Multimodal)。简单来说,就是让AI能同时处理文字、图片、声音、视频这些不同形式的数据。这样就能打破只处理一种数据的限制,给用户提供更全面的解决方案。
它之所以重要,是因为从市场角度看,当前许多大模型厂商都在围绕自己的核心业务,深耕多模态技术,这种依托业务根基的发展方式让模型更具竞争力。
比如:
阿里推出通义大模型系列,针对金融、医疗、娱乐这些行业进行定制;还有Qwen系列模型,Qwen-Math搞数学,Qwen-Coder为编程设计,Qwen-VL理解图片视频内容。
阿里还有个M6模型,专门针对电商场景设计商品、写文案、创作虚拟主播剧本等等,这些模型在适应不同场景和细分领域上都很强。
再看看豆包大家族,更是大力出奇迹。
它有两个主要的模型,一个叫 Pro,针对大规模文本创作的;另一个叫Lite,满足轻量化定制应用需求。
除此之外,还有音乐语音模型、声音复刻模型、文生图模型、图生图模型、视频模型,甚至角色扮演和同声传译的模型都有。他们把模型应用到了各种工作场景,到处都能看到他们的身影。
所以,Kimi肯定要通过多模态布局来核心竞争力。
话说回来,像字节和阿里这样的公司,在商业化大模型时有个特点:他们会将模型能力封装成具体产品,通过产品来验证市场需求,再利用产品实现商业化。
字节的豆包,它不仅是一个大模型的框架,还衍生出很多具体的产品,比如“即梦”。
主要用于文生图、文生视频、图生图、图生视频等领域,而且它已经进一步商业化,直接和市场上的可灵等产品进行对标和竞争。
但Kimi的产品包装能力还比较弱,虽然推出了一些功能不错的模型,但商业化的速度和市场验证的效率显得更慢一些。
这也导致Kimi在发展过程中可能更多依赖资本推动,这种模式比起快速形成产品闭环的路径,市场吸引力可能不够。
相比之下,Kimi在这一点上还有很大的进步空间。
如果能把模型能力包装成独立的产品推向市场,用产品来快速测试市场反馈,那么发展速度可能会更快。
因为,用户不是傻子,真正要让一个人付费时,反而会衍生出诸多真需求,而满足这些真需求,才是走向垂直细分更重要的一步。
因此,商业化和技术发展并不冲突,有能力不代表有用,这些问题,可能要Kimi进一步思考。
以上就是关于Kimi文生视频即将到来阴阴夏木啭黄鹂的上一句是什么全部的内容,关注我们,带您了解更多相关内容。
特别提示:本信息由相关用户自行提供,真实性未证实,仅供参考。请谨慎采用,风险自负。